Ce document relate l’intervention faite par Raphaël Velt et Jean-François Gigand le 4 avril 2012 aux Rencontres SIG la Lettre pour la session De l’open DATA au crowdsourcing, chronique d’une révolution en marche.
Télécharger la présentation en PDF (diaporama sans les commentaires)
Si le mouvement de l’Open Data est dès l’origine porté par des idéaux d’implication, d’empowerment des individus, sa manipulation est-elle concrètement accessible à tous les citoyens, indépendamment de leurs compétences techniques, aussi bien au niveau du traitement informatique des données, des statistiques, des champs scientifiques couverts par les données (sciences sociales, géographie, etc.) que des ressorts juridiques liés aux sources de données ? L’ouverture des données ne risque-t-elle pas de ne faire qu’aggraver la fracture numérique ?
Des exemples de tels regroupement de compétences variées existent pourtant déjà. On les retrouve dans des projets aussi divers que Wikipédia, Open Street Map et le monde du logiciel libre.
La seule interconnexion des individus ne suffit pas, les plateformes qui porteront l’Open Data de demain doivent également offrir une interopérabilité au niveau des données pour connecter formats, logiciels et projets. Cette interconnexion peut être fournie d’une part par l’hébergement des données sur des plateformes de Cloud Computing, d’autre part par l’usage de métadonnées sémantiques, en utilisant les standards du Web Sémantique définis par le W3C.
Nous ferons un panorama des plateformes sociales et sémantiques existantes pour dégager les tendances et présenter notre vision de technologies contributives qui permettront de véritablement rapprocher données ouvertes et citoyens.
Les auteurs se sont rencontrés à l’occasion du concours concours Géoportail 2010 organisé par l’IGN dont ils furent tous deux lauréats.

Raphaël Velt est chargé de développement à l’Institut de Recherche et d’Innovation (IRI).
L’IRI, fondé en 2006 au sein du Centre Pompidou par le philosophe Bernard Stiegler, est depuis 2008 une association regroupant des acteurs académiques et industriels des mondes de la culture et des nouvelles technologies: l’Ensci, France Télévisions, l’Institut Télécom, Microsoft France, Alcatel-Lucent, le Centre Pompidou, le Centre de Culture Contemporaine de Barcelone (CCCB), le Goldsmiths College de l’Université de Londres et l’III de l’Université de Tokyo.
L’IRI est une association de recherche dans le champ des Digital Studies, qui participe à des projets de recherche et conçoit des outils numériques répondant à des problématiques variées : Écologie de l’attention, Figures de l’amateur, Design du nouveau monde industriel, Philosophie et Ingénierie du Web et des métadonnées, Technologies relationnelles, réseaux sociaux et outils de transindividuation, Mobilité et motricité dans les pratiques culturelles instrumentées.

Jean-François Gigand a fondé la société Geonef en 2011, spécialisée dans la conception et le développement de portails web cartographiques.
Geonef focalise ses activités sur l’innovation autour de la cartographie interactive en ligne, autour de deux projets phares :
La plateforme SIG web qui permet d’éditer des cartes en lignes et se les partager autour de cercles de collaboration. Elle fournit un ensemble de couches cartographiques telles que les cartes OpenStreetMap, Google, Bing, Stations de Vélibs ou limites de communes.
Les Itinéraires de Voyage permettent aux voyageurs d’éditer un blog cartographique. Chaque étape est située sur la carte afin que l’itinéraire s’y dessine. Les récits et photos sont présentées en colonnes et défilent dans une frise chronologique.
Les principaux acteurs de l’Open Data soulignent son caractère émancipateur :
Internet peut fortement contribuer […] à replacer les citoyens au cœur de la République
— Séverin Naudet, directeur de data.gouv.fr
Accéder aux données, c’est donner [aux citoyens] la possibilité de coproduire la décision publique avec l’exécutif
— Dominique Cardon, sociologue
L’Open Data est rattaché à un vocabulaire désignant une nouvelle relation entre les citoyens et ceux qui les gouvernent :
Publication ne signifie pas accessibilité.
Pour faire sens d’un jeu de données publiques, il faut des connaissances :
Pour ceux qui n’ont pas ces compétences, l’ouverture des données peut même être susceptible d’accroître la fracture numérique
Pour construire des applications pertinentes des données ouvertes, il faut donc associer les compétences, que ce soit au sein d’une équipe (entreprise, laboratoire, cercle amateur…) ou entre équipes par le biais d’Internet, à la façon des logiciels libres.
Le grand potentiel de l’OpenData ne peut se développer qu’à cette condition.
Il s’agit non seulement de connecter les compétences complémentaires (ce qui n’est qu’un moyen), mais d’encourager les initiatives par le tissage de liens sociaux de nature à stimuler la contribution.
L’Etat et les collectivités doivent trouver leur juste rôle, autrement que dans une approche top-down.
Actuellement, il y a relativement peu d’incitation à donner accès à ses données.
Il faut créer des cercles vertueux pour les impliquer :
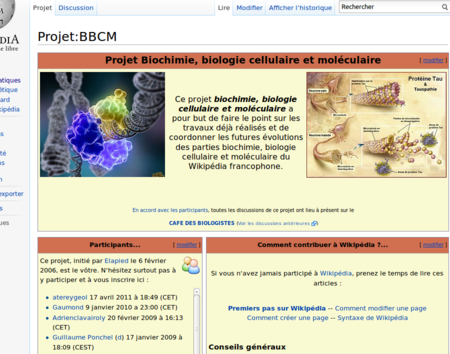
Wikipédia est un formidable succès de la collaboration à travers Internet. Intéressons-nous à cet exemple pour dégager les catalyseurs de sa réussite en tant qu’œuvre collaborative.
Le projet a permis de rassembler toutes sortes de compétences dans un but commun : la réalisation d’une encyclopédie.
Ces compétences interviennent à plusieurs niveaux :
Contrairement à l’éco-système recherché de l’OpenData, Wikipédia est défini par un objectif unique : construire une encyclopédie du savoir humain. Même si cet objectif est très ambitieux, si le mode de collaboration mis en œuvre est inédit dans son ampleur et sa concentration, le produit encyclopédique n’est pas en soi une innovation.
Dans le cas de Wikipédia, chacun des contributeurs pouvait dès le début se représenter l’objectif souhaité, grâce à la culture du savoir héritée du siècle des Lumières.
Cet objectif est compatible avec le choix d’une plateforme centralisée pour gérer l’édition et la consultation du contenu. La Fondation Wikimedia est l’autorité qui la supervise. Il y a donc une certaine centralisation qui facilite l’efficacité du projet, tout en restant discrète.
Un objectif clair et partagé et une entité centrale : un contexte stable et probablement nécessaire pour la réussite d’un défi inédit, celui de rassembler tant de contributeurs différents dans la production efficace d’un contenu gigantesque.
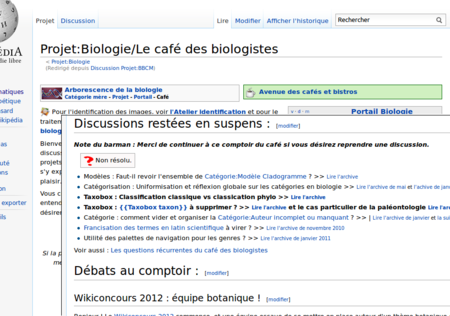
Wikipédia contient différents espaces d’articles :
Il est intéressant de noter que ces espaces fonctionnent de la même façon, avec leurs articles propres. Ce qui revient à dire qu’avant de créer une encyclopédie du savoir humain, les contributeurs créent une encyclopédie de la contribution Wikipédia (au sens technique), qui se renouvelle au fur et à mesure des chantiers spécifiques.
D’emblée, les concepteurs de Wikipédia ont bâti une méta-encyclopédie avec le même soin que pour l’encyclopédie elle-même.
OpenStreetMap est une cartographie libre du monde entier, réalisée par une multitude de contributeurs. OpenStreetMap est pour la carte interactive ce que Wikipédia est pour l’encyclopédie en ligne !
Ce projet a de nombreux points communs avec Wikipédia, comme sa nature libre et collaborative ou son objectif universel. Nous nous intéresserons donc à ses spécificités.
En effet, par rapport à l’encyclopédie, la conception de la carte demande des techniques plus spécifiques (dorénavant accessibles aux non-professionnels à travers les appareils GPS). En revanche, son objet est universel : le terrain est plus concret que le savoir.
Alors que Gutenberg inventât vers 1440 le moyen de diffuser le savoir à grande échelle, les cartes géographiques sont longtemps restées propriété du pouvoir royal ou de l’Etat-Major. La communauté scientifique a depuis repris cet héritage en le développant considérablement, mais les citoyens sont restés jusqu’ici des simples consommateurs de cartes.
La révolution sociétale que permet Internet se retrouve évidemment dans la cartographie, où les citoyens s’approprient la production de cartes. OpenStreetMap est à ce titre le projet phare de cette révolution de la cartographie, étant donné l’objectif global que représente la couverture topographique du monde entier et l’ampleur de la collaboration dans cet objectif[1].
La carte multi-échelle produite, visible sur la page d’accueil du projet, n’est que le plus petit dénominateur commun des rendus visuels de l’immense base de données géographiques construite. Cette base peut être valorisée sous des formes bien diverses, selon les besoins visés ([2], cartes de villes[3], calculs d’itinéraires[4]…). Elle peut aussi être exploitée dans des contextes autres que des plans géographiques, ouvrant la voie d’un large champ d’innovations[5].
La constitution de cette carte globale à la Google Maps était d’un intérêt suffisant pour démarrer et entretenir le projet. C’est en tout cas la valeur la plus immédiatement visible et la plus médiatisée, en tant qu’alternative à Google Maps.
Or sa plus grande valeur réside dans la multitude infinie d’application dérivées. Les base de données elle-même étant exploitable en amont de la production de plans topographiques laisse libre cours aux innovations, qui apportent leur propre part de valeur.
La base OpenStreetMap est donc un concentré de valeur : c’est là que se concentre la plus grande valeur, actuelle et potentielle, qui vient ensuite stimuler la création en amont et irriguer celle en aval.
Le produit – la base de données – n’est qu’une dimension du projet, qui est un cas d’étude pertinent dans notre analyse sur la collaboration autour de l’OpenData. Nous avons vu comment le produit visible et quantifiable concentre une grande valeur, dont c’est la densité qui permet l’émulation d’activités canalisées par des projets divers où cohabitent initiatives amateurs, recherches scientifiques et applications professionnelles.
Le projet OpenStreetMap sous le feu des projecteurs stimule l’auto-didactie chez des non-prefessionnels, sensibilise ses acteurs sur les questions de licence et de droits et sur les multiples aspects du travail en équipe et des problématiques croisées du traitement informatique avec les mesures du terrain.
Ce sont autant de compétences et d’expérience qui se développent et participent à l’économie formelle ou informelle : structures associatives, création de startups, mutation des entreprises d’un modèle consumériste pur vers un modèle contributif, etc.
OpenStreetMap est non seulement un concentrateur mais également un condensateur de valeur, dans le sens où son intérêt présent est suffisant pour attirer les contributions de tous bords (État, collectivités, entreprises et amateurs) dont la plus grande valeur est potentielle. C’est l’aspect de condensateur qui permet d’accumuler de la valeur le temps que se développent la grande diversité des usages et les technologies permettant de valoriser la richesse accumulée.
Le rôle de condensateur est important dans une situation de mutation : de nouveaux modèles économiques se développent, la mobilité et la société connectée induisent de nouveaux besoins. Cet aspect se retrouve dans l’éco-système des données ouvertes où la volonté politique a devancé – anticipé ? – les besoins de services innovants en bout de chaîne. En effet, si l’offre a besoin de la demande pour se développer, la demande a également besoin de l’offre pour se manifester, tout spécialement dans le cas du numérique où la mutation est profonde. Cette dépendance mutuelle rappelle ce qu’on appelle « dead lock » ou « Interblocage » en informatique. Sur le plan économique, des condensateurs de valeurs comme OpenStreetMap permettent d’éviter cette situation en croisant des intérêts multiples suffisants au sein d’un projet, ce qui permet leur accumulation sans dépendre de la demande qui peut se développer plus tard.
GitHub est une plateforme Web très populaire d’hébergement de code source logiciel. Elle fournit de puissants outils de collaboration en couplant l’aspect social avec des fonctionnalités de gestion des modifications (gestion de version).
GitHub est gratuit pour le code source ouvert, et payant pour les utilisations privées où l’accès au code source est réservée à un groupe restreint d’utilisateurs. C’est donc une plateforme de choix pour les logiciels libres où le partage du code source et la facilité de contribution est un facteur clef de succès[7].
De nombreux développeurs très expérimentés disent que GitHub a changé leur manière de développer du code. GitHub n’est pourtant qu’une plateforme sociale de partage de code source, il est compatible avec tous les langages de programmation pourvu qu’il s’agisse de lignes de texte. Mais lorsqu’on travaille en équipe, en particulier dans une communauté ouverte où toute personne peut contribuer sans formalisme préalable, la façon de structurer le code source logiciel et d’en planifier le développement sont fortement influencés par la façon de communiquer et de se partager le travail effectué.
On constate que de nombreux projets de logiciels libres, petits ou larges, ont migré leur dépôt de sources vers GitHub. Cette plateforme stimule la contribution ; elle est devenue la référence et son slogan Social coding a fait ses preuves. Elle est pourtant réservée aux contributeurs, et n’est pas utile à tout un chacun comme peut l’être Wikipédia. Au contraire, elle s’efface comme outil en favorisant la collaboration sur ses quelques 2 millions de dépôts hébergés qui concernent tous les domaines.
Intéressons-nous donc à ce qui fait sa réussite et dont on peut s’inspirer pour stimuler l’éco-système de l’OpenData. Au delà de l’outil, GitHub provoque un changement global sur la façon de collaborer, et au delà du code source logiciel, il en vient à être utilisé pour d’autres contenus, comme les articles de presse[8], la description de collections de musées[9] ou le génome humain[10] !
Le bouton fork pour cloner un projet sur GitHub. Le chiffre 1130 à droite est le nombre de clones existants pour cet exemple de projet.
GitHub est construit sur la logique du très populaire gestionnaire de version : Git.
Développé à l’origine pour gérer la collaboration autour du noyau Linux, cet outil permet de garder la mémoire de tout l’historique des modifications sur le code source. Il permet de visualiser qui a fait quoi à quel moment, et de fusionner les travaux respectifs de chacun. Par rapport à ses concurrent de l’époque, il fonctionne dans un principe décentralisé où chacun peut cloner le dépôt central avec tout l’historique afin de travailler indépendamment sur ses propres branches de développement. Ainsi, chacun conserve une liberté totale sur son travail sans perdre en efficacité pour le réintégrer au dépôt officiel.
Cela permet en outre de cloner le clone. Lorsqu’un développement particulier ne peut être (encore) inclus dans le dépôt central, le dépôt concerné devient en quelque sorte le dépôt central de ce développement là, que d’autres contributeurs peuvent cloner pour y apporter des améliorations et les réintégrer dans ce dépôt central-intermédiaire. Plus tard, tout ce travail peut enfin est réintégré au dépôt central aussi facilement. Plus qu’une possibilité, cette façon de faire est devenue un réflexe au grand bénéfice du dynamisme des projets.
GitHub s’appuie sur ce système. Tout utilisateur peut en un clic cloner les projets d’autrui pour y apporter des modifications, que ce soient de simples corrections ou des ajouts substantiels. S’il souhaite voir son travail réintégré au projet d’origine, il en fait la demande à l’auteur, qui visualise les changements proposés ligne par ligne avant de confirmer ou infirmer la demande.
GitHub propose cela par une interface Web belle et concise, réduisant d’autant la barrière de l’apprentissage et le frein psychologique.
La possibilité de cloner un travail est un principe clef. Tentons maintenant d’en comprendre les effets concrets.
Le fait de cloner (fork) un projet le fait apparaître dans la liste de ses propres projets. Il n’y a pas de différence entre un projet que l’on démarre soi-même et un projet qu’on récupère d’un autre. Et cela d’un seul clic de souris !
Le clone peut alors être modifié comme si l’on était l’auteur originel, sans rien demander à personne.
La barrière au démarrage est ainsi levée, autant sur le plan technique (simple clic) que psychologique (aucune personne à contacter). Cela stimule considérablement la contribution.
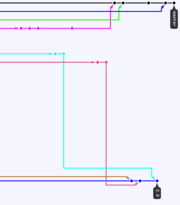
Exemple de généalogie des clones
Les modifications réalisées sur le clone sont visibles par tous. Puisque le clone apparaît comme un projet indépendant, il peut être cloné à son tour.
Si l’auteur du premier clone prend dans son travail une direction différente de celle suivie par l’auteur de l’original, une autre personne peut être intéressée par cet apport spécifique et cloner le clone au lieu de l’original. Et ainsi de suite… L’auteur du clone originel devient alors porteur d’une nouvelle branche de développement et en devient la référence, animant la collaboration autour de son apport.
Ainsi peuvent émerger des idées et des apports, car 3 limites sont levées par rapport à l’auteur originel : celle de ses idées, de sa volonté et de sa capacité de coordination.
Globalement, cela fait gagner à chaque projet une grande valeur potentielle. En pratique, de nombreux projets gagnent en contributions et s’en trouvent stimulés.
De nombreux projets en logiciel libre utilisent le système Git pour gérer le code source, et beaucoup d’autres souhaitent l’y migrer. Lorsque Git est utilisé, diffuser le code source sur GitHub n’implique pas de changement technique dans la façon de gérer le projet. La diffusion sur GitHub n’est qu’un clone supplémentaire du dépôt hors-GitHub habituel.
Inversement, il est facile de cloner ailleurs un projet hébergé sur GitHub, par exemple, à même sa propre machine, et c’est d’ailleurs ainsi que les développeurs travaillent.
GitHub s’intègre ainsi parfaitement au schéma organisationnel d’un projet existant, en y ajoutant le partage facile grâce à son interface graphique.
De plus, GitHub fournit les outils habituels de gestion de projet comme la gestion de tâches, la visualisation de modifications du code et la documentation du logiciel. Ce sont les outils habituels dans la gestion de projets logiciels, utilisés dans toutes les entreprises de développement depuis plus de 10 ans.
Ces éléments contribuent à la valeur du service rendu par GitHub, en diminuant ce qu’on perd en l’utilisant. Perdre peu et gagner beaucoup.
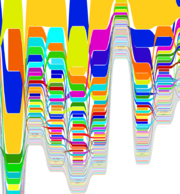
Graphique représentant les volumes des contributions par utilisateur
Ce n’est pas pour rien que l’équipe de GitHub a choisi pour slogan Social coding. Comme ailleurs, le social, est représenté par création de liens entre les personnes, ayant comme support les contributions respectives (liens entre les personnes et les créations d’autres personnes), avec un second degré : créer des liens et voir les liens des autres, dans une certaine mesure.
Sur GitHub, cela passe à travers différentes possibilités :
Ces trois derniers points sont les plus notables car ils stimulent la contribution. C’est une forme de gratification, lorsqu’on visualise sa notoriété.
Au delà de la question de l’égo – qui ne doit pas être négligée –, il s’agit de mesurer sa propre implication vis-à-vis des autres et de leurs travaux et de valoriser les connexion établies. C’est un retour sur sa propre action, qui responsabilise à des degrés divers. Ce retour permet de tenir compte dans ses travaux de leur impact dans des travaux dérivés.
À l’inverse, réintégrer ses modification sur un clone dans le projet d’origine passe par une demande au propriétaire du projet pour que celui-ci analyse la contribution pour évaluer sa pertinence. S’en suivent des messages, tout particulièrement si l’auteur demande des ajustements sur la contribution afin que celle-ci soit compatible, par exemple. Les deux personnes ont alors un lien de mutuelle reconnaissance : l’auteur envers le contributeur pour son apport, et le contributeur envers l’auteur pour la valorisation de son travail dans l’ensemble.
Scraper Wiki est un exemple de plateforme contributive autour de la problématique de l’extraction et du traitement de données.
La plateforme ScraperWiki s’articule autour de modules d’extractions nommés scrapers.
Elle fait collaborer :
Les modules peuvent être écrits dans trois languages de programmation très répandus :
Elle favorise l’open source :
La plateforme suit le modèle PaaS (Platform as a Service, Plateforme en tant que Service) et fournit :
Elle permet l’interopérabilité des données.
Pour ses usages, ScraperWiki permet d’une certaine manière d’ouvrir soi-même des données, en permettant l’accès à des données accessibles publiquement mais n’étant pas dans des formats suffisamment pratiques pour les exploiter directement. ScraperWiki n’adresse pas la question des droits à la réutilisation des données (les licences n’y sont pas discutées), ni la liaison entre les données (web de données/web sémantique).
CKAN est une plateforme développée à l’initiative de l’Open Knowledge Foundation. C’est un logiciel libre qui organise le stockage et le catalogage de données, que chacun peut installer sur son propre serveur.
Elle est utilisée pour la plateforme officielle des données publiques du Royaume-Uni et par de nombreuses autres initiatives comme par exemple nosdonnees.fr du Regards Citoyens.
Sur CKAN, les données sont organisées par paquets avec gestion des mises-à-jour, à l’instar de ce qui se fait pour les logiciels.
Chaque paquet se décrit lui-même : ressources téléchargeables, méta-données, mais aussi l’historique des anciennes version.
L’objectif de cette gestion par paquet est de permettre leur utilisation automatisée par des logiciels externes. Par exemple, leur exploitation croisée par un système de visualisation complexe est plus facile, notamment pour sa maintenance : les jeux de données sont interchangeables plus facilement tout comme leur mise à jour.
CKAN se concentre sur la gestion des méta-données : l’organisme source, l’auteur, le mainteneur, les dates, versions, catégorie, licence…
Les méta-données sont normalisées, tout en permettant de définir davantage de champs selon la nature du jeu de données et la volonté de son mainteneur.
Les méta-données sont au cœur du système et utilisées par le moteur de recherche intégré, l’accès via l’API, etc. Les données elles-mêmes peuvent être hébergées indépendamment et seulement référencées sur CKAN, qui n’est alors que le catalogue.
CKAN est utilisable via son API, qui permet à des logiciels d’utiliser les services de la plateforme CKAN de façon automatisée (API signifie application programming interface).
L’API est l’une interface d’utilisation pour les logiciels. Sans elle, l’utilisation du service est réservé aux seuls utilisateurs humains. L’API permet d’industrialiser l’utilisation des méta-données en les exploitant au sein d’autres systèmes.
L’API n’est pas un avantage, mais une condition de l’ouverture des données. En effet, les utilisateurs humains ont déjà accès aux données publiques depuis 1978[11]. La différence avec l’open data, au delà du basculement depuis une logique de demande vers une logique d’offre (guichets uniques de la données, etc.), réside dans la possibilité de structurer le marché autour de l’exploitation des données publiques.
Sans API, pas d’exploitation industrielle. C’est pourquoi la plupart des portails d’accès aux données l’intègrent évidemment. En dépit des apparences, l’API est la seule interface indispensable. Lorsqu’une API existe, tout acteur peut développer une interface humaine faisant le lien entre l’utilisateur humain et les données via l’API. Ainsi peuvent émerger de multiples interfaces d’accès au données, complémentaires entres elles, permettant la diversité nécessaire au développement de ce marché tant souhaité dans la volonté politique autour de l’open data.
CKAN étant un logiciel libre que tout acteur peut exploiter indépendamment, un réseau d’instances CKAN interopérable peut se développer. Chaque initiative isolée obtient davantage de valeur potentielle car une application dérivée pour l’une sera directement ou facilement exploitable avec une autre, augmentant l’intérêt de toute application.
L’interopérabilité est permise par cette répartition en multiples instances indépendantes combinée à l’API et à la forte structuration des méta-données.
À partir des clefs de succès dégagées dans l’analyse des cas d’exemple précédents, dégageons maintenant les axes d’efforts de nature à stimuler l’écosystème des données ouvertes.
Le terme écosystème est ici employé pour englober la diversité des acteurs en jeu (services publics, entreprises privées, monde associatif, amateurs…), que ce soit dans la production de données que leur exploitation à tous les stades de la chaîne de transformation. Mais cet ensemble n’a de sens que dans son intégration dans la société, qui est l’écosystème global.
Dans cette analyse, on peut grandement s’inspirer de l’écosystème des logiciels libres qui s’est développé à partir d’initiatives personnelles pour finalement s’intégrer dans le marché logiciel. Il est à la fois modèle économique et modèle de développement ; objet et moyen. C’est aujourd’hui un liant essentiel à l’économie numérique à tous les niveaux et tout spécialement pour l’innovation.
Un projet stratégique concentre sous une même bannière le croisement d’intérêts multiples. Son objectif doit être suffisamment général pour englober la diversité des intérêts, mais suffisamment particulier pour permettre la cohésion organisationnelle et technique.
Nous avons vu comment Wikipédia et OpenStreetMap sont tous deux des exemples de projets stratégiques. Leur portée est globale mais leur objectif est clair.
Ces projets ne peuvent pas être portés par un unique acteur privé, mais le soutien d’entreprises est souvent indispensable, comme on peut l’observer pour les logiciels libres.
L’interopérabilité est indispensable pour lier les contributions entre elles. Littéralement, il s’agit de faire inter-opérer les services et les données.
L’interopérabilité ne concerne pas seulement les données, ou l’accès aux données, mais aussi les applications de visualisation de données ainsi que les traitements intermédiaires.
Si l’interopérabilité doit être pensée de manière théorique, elle doit être accompagnée par des besoins concrets. Elle doit être développée de façon empirique. C’est aussi tout l’intérêt des projets stratégiques évoqués plus haut, où l’interopérabilité n’est pas une option mais une condition de l’utilisabilité des services développés (OpenStreetMap est un bon exemple).
Ici, les standards sont bien plus importants que les normes. Les processus de standardisation sont importants dans leur rôle de structuration de l’interopérabilité.
En revanche, il faut éviter l’écueil de l’excès de normalisation. La normalisation ne doit pas intervenir trop tôt. Les standards de facto émergent des besoins concrets, où l’expérimentation permet la lente maturation de tel ou tel domaine et niveau d’interopérabilité.
Nous préférons ainsi parler des interopérabilités que d’une interopérabilité, car c’est le fruit de la généralisation au cas par cas d’interfaces techniques communes.
Les méta-données sont des données. Il ne faut pas cloisonner données et méta-données. Les 2 doivent être adressées de la même façon.
Le Web s’est construit sur des liens textes.
À présent que les applications multimédia prennent de l’importance, celles-ci ne doivent pas être seulement des productions finales opaques, exploitables par les seuls consommateurs humains.
Les travaux de standardisation du W3C vont dans ce sens. Le Web sémantique est de plus en plus appelé Web de données.
Cet article a seulement fait l’analyse de ces quelques plateformes collaboratives que sont Wikipédia, OpenStreetMap, GitHub, ScraperWiki et CKAN. Il y en a évidemment bien d’autres.
La prise de conscience de l’importance de l’interopérabilité et des liens sémantiques est de plus en plus réelle, dans la sphère scientifique évidemment mais aussi pour les projets privés et probablement bientôt dans la volonté politique.
Rappelons-nous que le mouvement Open Data est relativement récent, puisque c’est le président Obama qui l’a popularisé avec le thème Open Government cher à sa campagne de 2008.
L’expression Open Data est bien souvent utilisée pour désigner les données publiques ouvertes, alors que le terme en soi désigne tout type de données ouvertes, y compris celles que les entreprises privés pourraient rendre disponibles. Il est fort à parier que le fameux écosystème de la donnée dont on parle se développe dans la complémentarité des données publiques, privées, et leur croisement avec des données personnelles entre autres.